AWSのRedshiftについて、Azure SQL Data Warehouse と比較

オンプレミスDataWareHouseの初期構築には数千万円~億単位の金額が発生します。2013年6月のAWSサミットにて、2013年6月5日にローンチされたクラウド型データウェアハウスのRedshift(東京リージョン)についてまとめました。当時、東京リージョンのRedshiftは世界で4番目のローンチとの事です。世界4番目とか、いい響きですね!
クラウド型データウェアハウスのAWS Redshiftのメリット
- イニシャルコスト不要
- 物理面のマシン管理が不要
- インストールやバックアップやパッチの適用はAWSに依存できる
- 監視サービスもローンチされている
- 費用対効果が非常に高い
メリットやデメリットなど、ローンチに向けて非常に力を入れてきた事がうかがえる発表が行われています。
クラウドPaasのRedshiftが初期費用/スケーリング/冗長構成など、DataWareHouseお手軽化の大革命を起こしました!と言っても過言ではない、グローバルメジャークラウド達のDWH(Data Ware House)についてです。
クラスタって何?
100台や200台などのマシンを1つにまとめあげて1つのマシンとして扱う(振る舞う)時の大きなかたまりのこと。8つのスライムがくっついて1つのキングスライムになっている感じ。軍隊蟻はたくさん蟻が集まっていても1つに再形成されてないから微妙に違う。複数の個体が合体して、大きくなったけど1つとして機能してること。物理のオンプレミスで行うと手間とお金が異常に必要で無理だけど、物理のオンプレミス会社で働く方であれば、クラウドを使うと簡単に速くコスパ高く出来る事がわかり、早々に事業が変わる。業務内容が変わる。物理のイメージが出来る分、クラウドだけの学習で動く若手よりも(若くないですが、私もオンプレ経験はありませんw、空想クラウド世代で、若いつもりですw)、いざ!という時、きっと頼りになる技術者の方なんだろうなと思う。
物理的にクラウド会社のデータセンターをイメージする
ユーチューブで見てください。グーグルやMicrosoftやFacebookなどのキラキラしたクラウドデータセンターを頭の中にイメージしてください。国や地域別のリージョンがあって、同リージョン内にデータセンターの建物が複数、さらに1つの建物の中に複数コンテナ、さらにコンテナの中に複数ラック、さらにラックの中に最小単位として物理サーバーノードが複数ある!管理してる外人のおっさん、たぶん超高給、羨ましい!とかイメージしてください。物理オンプレミスの経験が無い人は、クラウドのイメージやデザインパターンの神経回路を頭の中に作ることから!紙に書いてもいいです。
ラックとクラスターは全然違う
ラックは物理的に1ラックに対して20ノードなど、全部同じラックやノードを使うのであれば、1ノードのサイズと1ラックのサイズによって数が規則的に決まる。ノード≒物理サーバー1台です。しかし、RedShiftでクラスタリングの場合、親分で司令塔ポジションの『リーダーノード』(マスターノード、コントロールノード)と数多くの子分『Compute Node』(スレーブノード、データノード)という構成で1つのDBとみなすという感じ。1台のマスターと100台のスレーブという感じ。大量並列処理 (MPP:Massively Parallel Processing) アーキテクチャと言われる。クラウドすごいー。
DataWareHouseは大企業のひとり情シスが詳しい事も有りそう・・・
大企業のひとり情シスなど、技術スゴイけど正当な報酬を得られない、つらいポジションの人が、詳しいケースありそう・・・。勝手な妄想です。こういう人こそコンテンツマーケで技術ブログで自分の価値を世間にアピールしないとダメです。勤務先に「他社から引き抜き誘いもらってます!」くらい突きつけられる様な技術ブログを作る!そうしないと、技術がわからない硬直上層部は、何もわからず、テクノロジーで競合に負けて、売上減って、給料を勝手に下げられるだけ。『世間の優秀なクラウドインテグレータから誘われてる、給料、倍です!さよなら~!』とか、会社に突き付けられる環境を自分で作るべき。それで変わらない会社は、そのうち潰れる。その程度の識別眼しか持たない会社であれば、退職して次のステージに行ったほうがいいと思う、人生の無駄。
そうしないと、睡眠時間も評価も無くなる。技術者はいつの時代も多数派ではなく少数派です。しかし、技術者のテクノロジーは時代すら変える力を持つ。ひとり情シスは、たとえ上層部が認めていなくても判断責任が経営者レベルです。もっと自信を持つべき。同じ視点で客観的に評価してもらえる境遇が無いなら、自ら境遇を作るしかない。社内人事評価システム構築は経営者レベルの仕事。社内人事評価システムを作られないなら、評価してくれる人を社外に自分で作ればいい。ビジネスオーナーの経営者に定時退社なんてない。中小ベンチャーならなおさら。必然的に1人情シスは経営者視点を自育しなきゃいけない(難関)、サラリーマンを抜けて経営者エンジニアです。サラリーマンエンジニア思考を脱出できないとおそらく境遇は悪化の一途。
Qiita読み慣れしてるバックエンドエンジニアならワードプレスブログをphp含めて使いこなすのは難しくない。仮想化を提供する基盤側の会社までいかないと、バックエンド、インフラ系は技術者同士で評価できる組織は作りにくいと思います。結果的に、その会社もテクノロジーからどんどん置いていかれて市場競争で負けていく、余計に給料上がらない。クラウドテクノロジーを浅く使うだけで積極活用しようとしない上層部には、ショック療法しかないです。ブログ書いて転職で給料と待遇を上げるか、独立して立場を変えて相場価格を徹底的に調べ上げてその会社から仕事を請け負うか、評価のやり方がわからない上層部に他社の自己評価を突き付ける。客観的な指標は、IT技術が苦手で近寄る努力を避ける人に強制ショックを与えるにはいい。わかりやすい丁寧なコンテンツとか、きれいごとは即効性に欠ける。1人情シスさん、勝ち取れ!マジで頑張れ!愛と健康だけは失わないようにね!(酷)
クラスタ構成やノードの選択肢がある
AWSのRedshiftについては、dc1.large(SSD)、dc1.8xlarge(SSD)、ds2.xlarge(HDD)、ds2.8xlarge(HDD)などのノードタイプ選択肢があり、HDDの方がストレージはだいぶ大きい。『クラスタ構成(タイプ)』と『ノードタイプ』という名称分けで学習段階の早いうちに明瞭にわかりやすく表現してほしいです。Redshiftを学習していると『クラスタ構成(タイプ)』というキーワードが出現してくるタイミングが遅いです。
データウェアハウスって何?
テラバイトを越えるようなビッグデータを扱う時に使う、大きいクラスターデータベースみたいな感じ。Redshiftではペタバイトクラスまで扱う事ができる。分散処理技術のHadoop+Hiveよりも10倍速い上に、かなりコストが下がる。1.2TBのデータボリュームのクエリをHadoop+Hiveの1/10の速度でこなし、約150秒とのこと。1.2TB150秒!AWS Redshift はAzureであればAzure SQL Data Warehouse が定番の比較対象です。
完全互換ではないので要注意ですが、RedshiftはPostgreSQLっぽいクエリのアーキテクチャー。DBのテーブル構造でレコードのロー(横行)ではなくカラム(縦列)を単位として時系列でデータを扱うカラムナーデータベース。ググっていくつかの英語の記事を読んでいると、時系列に細かく差分を取り扱うので削除や更新をしない、という様な記事も見かけました。
DWH(DataWareHouse)は何のためにある?
1インスタンスのMySQLとか使っていて、10GBとか容量が肥大していてパフォーマンスが落ちたり、最適化しても容量ダイエット出来なかったり、データ分析やダンプやインポートでハマった。データ分割して出し入れも丁寧にやった。コールドバックアップによる復元とかも意味がない、やる気でない!だって、何もいいことない。うわっ!これ以上の操作ができない!次の操作に進みたいけど3日待ち!とか、ビッグデータのハンドリングは基盤が弱いと仕事にならないことがある。ビッグデータの取り扱いは結構な特殊分野です。そのため、ビッグデータ専用の基盤が必要とされています。DWH(DataWareHouse)くらいを使うビッグなデータだと、国内でも利用者は限られてくると思います。AI時代/ビッグデータ時代必須の基盤として、今後も利用が増える事は間違いないと思います。クラウドを根こそぎ受注するならデータウェアハウスは絶対に勉強するべき。S3などの静的ストレージやDataWareHouseなどの動的ストレージは、いわばAIの機械学習に対するデータ図書館です。根幹です。
AWS Redshiftか?Azure SQL Data Warehouseか?
マスターとスレーブで細かい課金システム、SQLserverとの互換性の高さ、短時間のスケーリング、起動/シャットダウン、オンプレミス連携、Visual Studioで扱える、など、AWS Redshiftに比べてAzure SQL Data Warehouseがリードしていると考えています。Microsoft はSQL serverで生粋のDBメーカーであることを鑑みると当然なのかもしれません。三菱東京UFJ銀行はAWSを選んだ。
失敗したことはリージョン選択(AWS失敗のど定番)
2017年6月現在、AWSでは『アジアパシフィック(東京)』のリージョンがあります。でも、学習中はデフォルトのオハイオをいつの間にか使ってしまっている、AWSあるある。AWS使うなら、何よりも先に、画面右上で「サポート」の左隣にあるリージョン変更!サブネット等のリソースが別リージョンで増えてしまい、リソース管理が煩雑になるので、無駄なアクティブリージョンやリソースはつくらない方がいいと思います。ElasticIPとかみたいに、記憶から消えたまま、謎課金の誘発因子となります。クラウドは沈黙のITヤクザ(負け犬の遠吠え)。
AWSのUIはリージョン設定が抜け落ちやすい。利用者にリージョンを問うタイミングとか、わかりやすさとか、よろしくない。UI的にヒートマップはZ型じゃない、レスポンシブウェブデザインを加味すると左寄り気味のI型がUIの基本思考だと思ってます。Azureは、リージョンをはっきり認識しやすい。Azure SQL Data Warehouseは東日本リージョンです。
リソースグループとネームタグによるリソース管理
クラウドの『リソース管理の使いやすさ』に目的を絞った比較記事って少ないけど、これ大事。タグの識別名を『RedsDevTest01』として目的を明示、値(value)には、『RedsDevTest01-VPC01』や『RedsDevTest01-SBnet01』や『RedsDevTest01-SecurityG01』など、「タグの識別名」+「それぞれのリソース分類名」を素直に入れる。部分一致検索に対応するため。01とか数字を入れるのも結構大事。テスト2回目とかあるし、その場合は02とか入れる。01を入れておかないとソートしにくくなる。ネーミングルール次第で今後の使い勝手が左右されるので重要。
AWSは初期デフォルトVPCが各リージョン毎に存在する
AWSは、新規でアカウント作ると初期デフォルトのVPCが各リージョン毎に自動で設定されていて、インターネットゲートウェイ、サブネット、ルートテーブル、ネットワークACL、セキュリティグループがデフォルトで存在する。その中でもサブネットの数がリージョン毎に異なり、アジアパシフィック東京リージョンは、デフォルトサブネットが2つ。このあと、クラスターを作ると、サブネットが3つになる可能性がある。覚えておかないとリソース管理がやりにくくなる。
とりあえず構築して使ってみる場合
VPCの中にEC2で仮想マシンを立てたことがあり、VPC、サブネット、インスタンスに対するセキュリティグループへのInboundなどのファイヤーウォール通信規則の設定をしたことがあり、AZ(アベイラビリティゾーン)も理解している人であれば問題無いと思います。また、クライアントマシンからGUIツールのAginity Workbench for Amazon Redshiftでインターネット経由接続する場合、インターネットゲートウェイをVPCにアタッチする事も忘れない様にしてください。
Redshiftのダッシュボードで青ボタンの『クラスターの起動』でスタートすると、EC2に自動的にセキュリティグループが自動で立ち、インターネットゲートウェイも自動で作られます。(デフォルト)パラメータグループとクラスターを結び付ける必要が有ります。スナップショットが何か1つのアクションに対して発効出来、自動と手動が選べる、S3に保存。
Virtual Private Cloud(VPC)、仮想ネットワーク系の確認
とりあえず既存デフォルトの各種リソース達の確認をしながら1つ1つのリソースに名前を付けていく。記事を書くのが大変なのでネームタグのkeyとvalueで案内した方式でネーミングしていく。各リソースへの名前は、以下の様に設定する際にクリックする部分が微妙にわかりにくいので要注意。以下の画像はデフォルトVPCです。
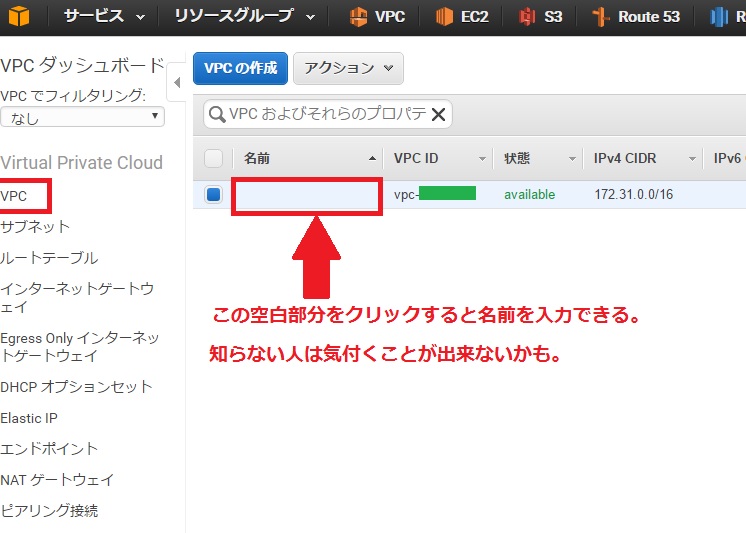
ダッシュボードで『VPC』にいく、デフォルトのVPCがある事を確認、VPCに名前を付ける『RedsDevTest01-VPC01』。ちなみにAzureではVirtualNetworkの仮想ネットワークがVPCに該当する。⇒インターネットゲートウェイに進み、同じくデフォルトのインターネットゲートウェイに名前を付ける『RedsDevTest01-IN-Gway01』。そして『RedsDevTest01-IN-Gway01』が『RedsDevTest01-VPC01』にアタッチされている事を確認する⇒サブネットに進み、デフォルトのサブネットが2つある事を確認し、『RedsDevTest01-SBnet01』『RedsDevTest01-SBnet02』と名前を付ける。それぞれ『RedsDevTest01-VPC01』のVPCと紐づいている事を確認する。
『クラスターの停止』は存在しない、『クラスターの削除』はある
ググると王者クラスソメソッドさんのAWS-CLIでRDSでもRedshiftでもCLI用の起動停止スクリプトやバッチが出てきます。素晴らしい!インスタンス(仮想マシン)とクラスターでは取り扱い方法がやや異なるので要注意!1匹狼の個人事業主は簡単に停止できるけど、社員が多い大企業はプレミアムフライデーなどの停止が大変難しい(スタバで仕事の続きをやっちゃうとか)、だから会社ごと消すしかない!という感じです!
スナップショットでクラスター停止、再起動
クラスターのスナップショットを取り、クラスターを削除までが停止。該当のスナップショットを選び、復元することが再起動。Redshiftのダッシュボードに学習用途で使った時のイベントが残って消せない・・・。APIかCLIじゃないとイベント削除はダメっぽいです。管理上紛らわしい。REDSHIFT-EVENT-2011のイベントはクラスター削除の履歴だ!と、覚えておく程度。リソース管理的な意味でデフォルトのパラメータグループは削除出来ない事も覚えておいたほうがいいです。リソース管理は、Azureのニューポータルが最強だと思ってます。
冗長化どうやるの?
学習中ですが、コールドスタンバイなら台数が半端ないです、このくらいのコールドスタンバイでダイナミックにスレーブを従えてインスタンスを操作できるのは王様気分かも(笑)
機械学習連携は?
学習中ですが、時間見つけて速くやりたい!
※間違っている部分などありましたら、ご遠慮なくコメントで突っ込んでください!暇を見て修正します。ユーザー皆様のために良質な記事を!人類の集合知を高める事に貢献したい。

