MicrosoftAzureでIaasのLinux仮想マシンに対してBackup and Site Recovery (OMS)を使う
Linux 仮想マシンの可用性管理のスクリーンショット画像です。この記事は、まだ、ベストプラクティスを見いだせておりません。ご指摘は歓迎しますのでお気軽に突き刺してください。
Azureのリソースグループについて運用環境を顧客毎やプロジェクト毎に分離し、IaasのLinux仮想マシンに汎用ストレージアカウントや可用性セットも設定している事が前提状態となります。
整理整頓や命名規則の整頓をしていない場合、あらゆる作業が煩雑になり、時間の無駄やミスが誘発されやすくなります。リソースグループは、長く賢く運営するために、接頭辞や接尾辞などの命名規則をフィーリングで識別しやすいものにすることを強くお勧めします。ディレクトリ別け無しで使っている様なレンタル共有サーバーのドキュメントルートと同じ様な状態は避けるべきです。思考リソースや時間を無駄に奪われ、見積上昇要因です。
リソースグループ命名の例
Active01ClientnameWebsitename20171120など、分解すると、Active01で本番環境(開発ならDev01)、Clientnameで顧客名、Websitenameでウェブサイト名、年月日という感じです。
Azureで可用性セットを設定したLinux仮想マシン1台を想定
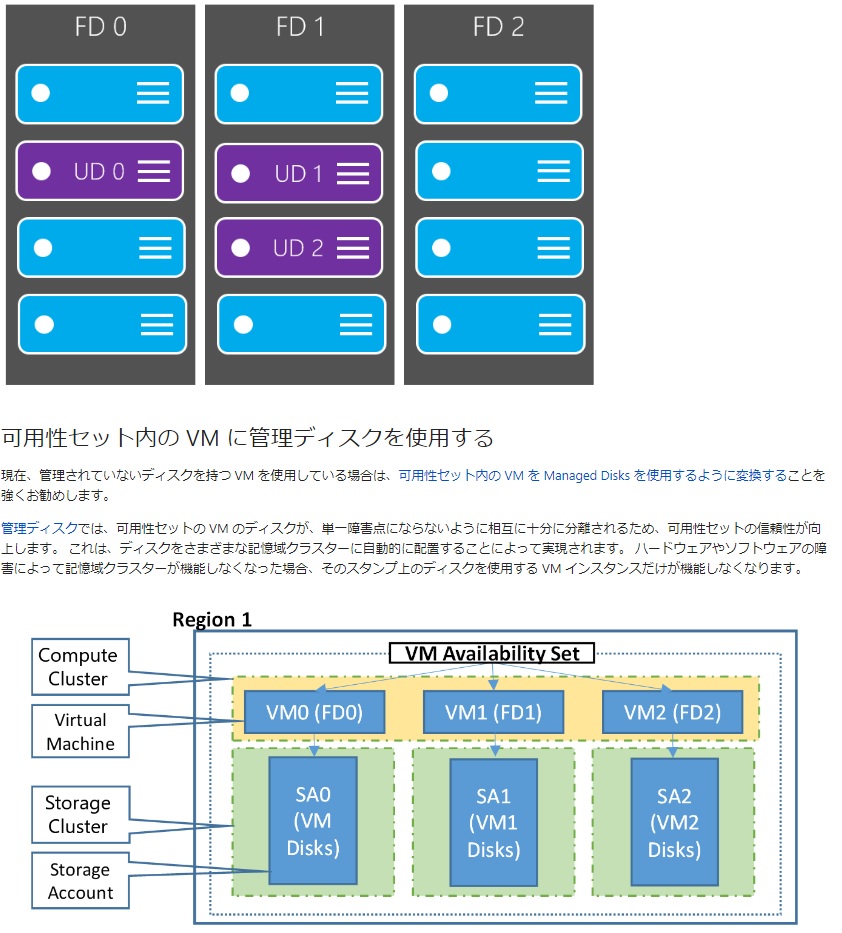
この記事ではバックアップ対象とするAzureのIaasで障害ドメイン(FaultDomain)更新ドメイン(UpdateDomain)の可用性セットを行ったLinux仮想マシン(プライマリ)1台としてシンプル構成を前提とします。バックアップは大きく別けると、バックアップ(非リアルタイム復旧)とレプリケーション(リアルタイム復旧)の2つに別れることも覚えてください。仮想マシン1台に対してストレージアカウントの設定をしていないと「バックアップ」の「VMの復元」の「ディスクの復元」でストレージアカウントの問題で行き詰まります。AzureのIaas本番環境では「可用性セット」も必ず設定してください。
ストレージアカウントの設定
Azureは仮想マシンを作ると、BLOBストレージにVHD(Virtual Hard Disk)が保管されます。仮想マシン1台に対して1つの汎用ストレージアカウントを取得する。
Backup and Site Recovery (OMS)でバックアップコンテナを作る
Azureポータル⇒新規⇒Backup and Site Recovery (OMS:Operations Management Suite)⇒作成⇒Recovery Services コンテナー(名前、サブスクリプション、リソースグループ、場所を選ぶ)⇒作成 にてまずはバックアップコンテナ作成となります。次に、バックアップポリシー(バックアップの頻度や時間)を設定するとバックアップコンテナの中に、バックアップアイテムとして複数のVHDが保管される様になります。バックアップポリシーは、DefaultPolicyが最初からあるので、DefaultPloicyを削除してバックアップポリシーを新規追加する事をお勧めします。バックアップポリシーの一覧をしっかり確認してください。コンテナの場所は、バックアップ対象とする仮想マシンのリージョンと同じにするか、別リージョンにするか?となります。この記事はAzure(プライマリ)対Azure(セカンダリ)を想定しており、対オンプレ想定の記事ではないです。
バックアップ
バックアップは過去のデータ保持となり、主に以下2つのジョブに別れる。リアルタイム復旧ではない。
- AzureのIaasのLinux仮想マシン1台(稼動中:プライマリ)からバックアップ取得
- 取得したバックアップデータから過去の仮想マシンを復元
『Backup』でAzure内で検索することで、『Backup and Site Recovery (OMS:Operations Management Suite)』が出てきますので選択してください。もしくは、Azureのポータルでバックアップ対象にする仮想マシン(プライマリ)を選択⇒仮想マシンの左ペインで「バックアップ」を選択し、バックアップポリシー(バックアップの頻度や時間)を設定する。海外リージョンで運用していてもUTC+9:00で大阪、札幌、東京の日本時間に設定する事もできる。同一のリソースグループ内で設定すると、Recovery Services コンテナーが新しく同一リソースグループ内に追加される。バックアップポリシーが設定されると、ジョブとして「バックアップの構成」が勝手に走る。「バックアップの構成」が完了していればおそらく問題無い。
バックアップポリシーを設定したら、「バックアップアイテム」にて紐づける仮想マシンを「バックアップの目標(ターゲット)」で設定する。「バックアップアイテム」から該当の仮想マシンに進むと「今すぐバックアップ」なども可能。
デフォルト状態のワードプレスLinux仮想マシンに対して、「今すぐバックアップ」をDS1_V2 Standardで約25分の時間がかかった。VHD作成25分という感じ。ジョブの実行経過時間が表示されているのは、便利。ジョブの成功/失敗管理のやりやすさがクラウドの真骨頂ですね。
AzureのIaasのLinux仮想マシン1台丸ごとデータを定期的に取得して保管して復元ポイントがバックアップポリシー通りに連なっていく。さらに保管したデータから仮想マシン(セカンダリ)を復元する。復元については過去の仮想マシン(プライマリ)の状態となり、リアルタイムな復元ではない。この記事ではオンプレ対Azureなどは含まず、Azure(稼動中仮想マシン)対Azure(復元後の仮想マシン)を想定する。リアルタイムな復元の場合、GEO(地理)冗長のレプリケーションなどを検討する必要も出てくる。
Backup and Site Recovery (OMS)の注意点
- ネットワーク構成のバックアップはされず、仮想マシンのみのバックアップデータ取得・保持(バックアップコンテナ)される。
- リージョンをまたいでバックアップコンテナを持つかどうか?
- Linux既存仮想マシンを上書きする形で仮想マシンを復元する機能は、最も欲しいタイプだが開発中の様子。
ネットワーク構成のバックアップについては、スクリプトでプレースホルダを作って扱わない限り、手動は避けられないと思われます。githubなどで探したら出てくるかも?「Site Recovery インフラストラクチャ」の「ネットワークマッピング」は、あくまでレプリケーション向けのネットワーク対ネットワークのマッピングで、バックアップではバックアップコンテナをリージョン指定します。また、バックアップ対象とする仮想マシンのリージョンと同一リージョン(ローカルリージョン)にバックアップコンテナを配置するのか、別のリージョンにバックアップコンテナを置くのか、選択が必要です。別リージョンを選択する場合、選択先のリージョンで仮想マシンサイズも含めて全く同じサービス構成は作られるのかどうか?など、別リージョンに環境を1つ構築する事になるので見積金額が全く変わる。この記事では、ローカルリージョンにバックアップコンテナを設置するパターンを想定しています。
VMの復元とファイルの回復
バックアップデータから過去の仮想マシンを復元については、「VMの復元」と「ファイルの回復」の2種類がある。「VMの復元」では、VMが丸ごと一つ新たに出来る。「ファイルの回復」では、バックアップしたデータの一部のみを復元する事が出来、既存VMのデータ変更が可能で、VMに存在するデータの一部を誤って削除した場合や、破損した等の一部分のデータのみ復元する事に適している。
VMの復元
「仮想マシンの作成」か「ディスクの復元」に別れる。
仮想マシンの作成
仮想マシン名 や リソースグループ名 をプライマリと同じ様に設定して上書きする事は出来ない。リソースグループを別に作り、DNSゾーンやロードバランサ―で切り替える事になる。ネットワーク構成を考え直すのが手間。復旧対象リソースグループの構成をよく覚えておくこと。復元は1~2時間かかる。復元された新しい仮想マシンは、ログイン情報なども含めて基本的に元の仮想マシンと同じものとなる。ディスクの復元が上手くいかない為、めんどくさいが、今のところ、実用化では、消去法でこの方法しかないと思われる。何度か検証してネットワーク構成を変更する手順書を作成しないと厳しい。仮想マシンが立ち上がるまでに普通のプロヴィジョニングと同じ程度の時間がかかる。
ディスクの復元
プライマリのLinux仮想マシンのTarget Storage Accountになっているか?他のリソースグループのストレージアカウントなどを参照してしまっていないか?確認する事が大事。これを実現するためには、仮想マシンを構築する際に「可用性セット」を設定する必要が有る。「可用性セット」は同一リージョン内のゾーン冗長という感じ。仮想マシン1台をある特定の時に戻すなら「VMの復元」⇒「ディスクの復元」が、バックアップ対象のLinux仮想マシンのディスクを過去にさかのぼる感じで一番便利と思われたが、早速、4秒で失敗した。Criticalレベルの失敗らしい。ストレージアカウントの種類によって失敗するものがある。落とし穴だ。以下はエラー文章。『Backup and Site Recovery (OMS:Operations Management Suite)』は、なぜ、これほど使いにくいのだろうか。落とし穴が異様に多い。バックアップが失敗しない様に簡単な構造にするべき。構造的なミスが多発しそう。使い方を理解するまで、検証に時間がかかり過ぎる。最も期待している方法だが、残念ながら未だに、実用化手順が見えない。インフラ系は検証に異常に時間を奪われる。
Only Basic/Standard storage accounts with locally redundant or geo redundant replication settings are supported. Please select a supported storage account.
おそらく以下が和訳。
復元操作に指定されたストレージ アカウントがサポートされていません – サポートされているのは、ローカル冗長レプリケーションまたは geo 冗長レプリケーションの設定が指定された Basic または Standard ストレージ アカウントのみです。 サポートされているストレージ アカウントを選択してください。
この記事の検証作業では、元からStandardでLRSでストレージアカウントを作っている、上記警告文の意味がわからない。ストレージアカウントのアクセス権設定に問題があるのか?可用性セットの障害ドメインや更新ドメインの確認が必要なのか?わからない。Backup and Site Recovery (OMS)は全体的に非常に使いにくい。
ファイルの回復
Linux仮想マシンの場合、スクリプトをAzureポータルからダウンロード、仮想マシンへスクリプトをインポート、スクリプトのパーミッションを0744、ユーザー:root、グループ:rootに変えてスクリプトを実行、パスワードをAzureポータルからコピーして打ち込む。敷居高め。実行すると英語で色々と聞かれる、基本的にはY返答が多くなる。
※復旧ポイントのボリュームはスクリプトが実行されるフォルダーにマウントされるため、スクリプト配置ディレクトリをスクリプト実行前に吟味する必要が有る。「仮想マシン名–年月日」というディレクトリ名でマウントされる。プライマリ仮想マシンのファイル達が自動的に上書きされるわけではない。便利ではない。
※スクリプトの実行には、CentOS6.5以降、など、要件があるので要注意。要件は、Azure での Linux 仮想マシンのファイルの復元についてを参照ください。
スクリプトが走り始めると、ISCSIというものが動き始める。
マウント解除など、ややこしい。Microsoftの日本語ドキュメントも散らばっていて、1箇所にまとまっていない。Linux仮想マシンのファイルの回復は商品パッケージ化するには使い勝手が良くない・・・。実用としては微妙。Azureポータル内でBackup and Site Recovery (OMS)のあたりで意見を求めるアンケートもやっている。ベータ開発途上版という感じは否めない。
バックアップコンテナー
バックアップポリシーを設定して、VHDを時系列に並べて保管するためのコンテナー。Azure Virtual Machine(Azure内の仮想マシン) , Azure Backup Agent(Windows Server) , Azure Backup Server(Hyper-V VM、Microsoft SQL Server、SharePoint Server、Microsoft Exchange、Windows クライアント)として3種に別れる。この記事では、Azure Virtual Machineを使う。
バックアップアイテム
設定されたバックアップポリシーの実体。この中に復元ポイント別のVHDが構成されていく。
バックアップジョブ
バクアップの構成、バックアップ、Site Recoveryなど、各種のジョブの実行状況を確認できる。
バックアップアラート
各種のジョブが失敗するとアラートが出る。ストレージアカウントの違いで4秒でディスクの復元が失敗した際は『Critical』と表示された。また、管理ディスク (Managed Disks) のサブスクリプション間やリソース グループ間の移行についてに記載されている通り、ディスクはサブスクリプションの変更に対応していない。新リソースグループを作り、ネットワーク構成の中身を丸ごとサブスクリプション変更しようとすると、ディスクだけサブスクリプション変更できない!などの厄介な問題がある。もしも、検証せずに商品化していたら!と考えるとゾッとする。ここ一番!と言う時にサブスクリプション変更がうまくいかない!など、窮地に立たされる。ディスクは、一度、VHDにエクスポートしなければならない。もしくは、Microsoftのサポートに頼むことが出来る。これは課金に関わる事なので、サポートプランに加入していなくても対応してもらえる。
レプリケーション
リアルタイムにデータの差分などを同期。障害発生時にリアルタイムで復旧する。リージョンをまたいでレプリケートしなければならない、基本的に同一リージョン内は不可。設定する前にリソースグループやネットワーク構成を別リージョンに準備しておく必要が有る。2017/11/21時点でプレビュー版。地理的なリスクヘッジとコストを考える必要が有り、転送データ量が多くなるほどコストが上がる。別リージョンに環境を1つ構築する事になるので見積金額が全く変わる。Azure Storage のレプリケーションでペアリージョン(プライマリとセカンダリの組み合わせ)の確認が出来る。
同一リージョン内の場合、WordPressでphp/MySQL(MariaDB)なら、lsync/rsyncとMariaDB Galera Clusterを使うという手もある。経験は無いですが、調べる限りGalera ClusterはマスターDBの変更なども柔軟で、かなり出来る子というイメージがある。プライムストラテジーのヨミドクター事例のAzureのCDPを見るとわかりやすい。オートスケールではないので仮想マシンは多いが、突発の負荷に対して安定したパフォーマンスを発揮できるCDPだと思う。
冗長ストレージ種類
ZRS(Zone Redundant Storage)・・・ゾーン冗長ストレージ。複数のデータセンター間でのデータのレプリケート無し。個別のノードで保持されるデータ コピーの数:3
LRS(Local Redundant Storage)・・・ローカル冗長ストレージ。複数のデータセンター間でのデータのレプリケート有り。個別のノードで保持されるデータ コピーの数:3
GRS(Geographically Redundant Storage)・・・地理冗長ストレージ。複数のデータセンター間でのデータのレプリケート有り。個別のノードで保持されるデータ コピーの数:6
RA-GRS(Read Access – Geographically Redundant Storage)・・・読み取りアクセス地理冗長ストレージ。複数のデータセンター間でのデータのレプリケート有り。1 次拠点に加えて 2 次拠点からもデータの読み取り可能。個別のノードで保持されるデータ コピーの数:6
Recovery Services コンテナーの削除
削除する前に、バックアップ アイテムを手動で停止/削除が先に必要。また、バックアップ取得中やバックアップから復元中の処理達の事をジョブと呼ぶ。「バックアップ取得のジョブが実行中」、「バックアップから復元のジョブが実行中」など。